We are excited to share the first models in the Llama 4 herd are available today in Azure AI Foundry and Azure Databricks, which enables people to build more personalized multimodal experiences. These models from Meta are designed to seamlessly integrate text and vision tokens into a unified model backbone. This innovative approach allows developers to leverage Llama 4 models in applications that demand vast amounts of unlabeled text, image, and video data, setting a new precedent in AI development.
Today, we are bringing Meta’s Llama 4 Scout and Maverick models into Azure AI Foundry as managed compute offerings:
- Llama 4 Scout ModelsLlama-4-Scout-17B-16E
- Llama-4-Scout-17B-16E-Instruct
- Llama 4 Maverick ModelsLlama 4-Maverick-17B-128E-Instruct-FP8
Azure AI Foundry is designed for multi-agent use cases, enabling seamless collaboration between different AI agents. This opens up new frontiers in AI applications, from complex problem-solving to dynamic task management. Imagine a team of AI agents working together to analyze vast datasets, generate creative content, and provide real-time insights across multiple domains. The possibilities are endless.
To accommodate a range of use cases and developer needs, Llama 4 models come in both smaller and larger options. These models integrate mitigations at every layer of development, from pre-training to post-training. Tunable system-level mitigations shield developers from adversarial users, empowering them to create helpful, safe, and adaptable experiences for their Llama-supported applications.
We’re sharing the first models in the Llama 4 herd, which will enable people to build more personalized multimodal experiences. According to Meta, Llama 4 Scout is one of the best multimodal models in its class and is more powerful than Meta’s Llama 3 models, while fitting in a single H100 GPU. And Llama4 Scout increases the supported context length from 128K in Llama 3 to an industry-leading 10 million tokens. This opens up a world of possibilities, including multi-document summarization, parsing extensive user activity for personalized tasks, and reasoning over vast codebases.
Targeted use cases include summarization, personalization, and reasoning. Thanks to its long context and efficient size, Llama 4 Scout shines in tasks that require condensing or analyzing extensive information. It can generate summaries or reports from extremely lengthy inputs, personalize its responses using detailed user-specific data (without forgetting earlier details), and perform complex reasoning across large knowledge sets.
For example, Scout could analyze all documents in an enterprise SharePoint library to answer a specific query or read a multi-thousand-page technical manual to provide troubleshooting advice. It’s designed to be a diligent “scout” that traverses vast information and returns the highlights or answers you need.
As a general-purpose LLM, Llama 4 Maverick contains 17 billion active parameters, 128 experts, and 400 billion total parameters, offering high quality at a lower price compared to Llama 3.3 70B. Maverick excels in image and text understanding with support for 12 languages, enabling the creation of sophisticated AI applications that bridge language barriers. Maverick is ideal for precise image understanding and creative writing, making it well-suited for general assistant and chat use cases. For developers, it offers state-of-the-art intelligence with high speed, optimized for best response quality and tone.
Targeted use cases include optimized chat scenarios that require high-quality responses. Meta fine-tuned Llama 4 Maverick to be an excellent conversational agent. It is the flagship chat model of the Meta Llama 4 family—think of it as the multilingual, multimodal counterpart to a ChatGPT-like assistant.
It’s particularly well-suited for interactive applications:
- Customer support bots that need to understand images users upload.
- AI creative partners that can discuss and generate content in various languages.
- Internal enterprise assistants that can help employees by answering questions and handling rich media input.
With Maverick, enterprises can build high-quality AI assistants that converse naturally (and politely) with a global user base and leverage visual context when needed.
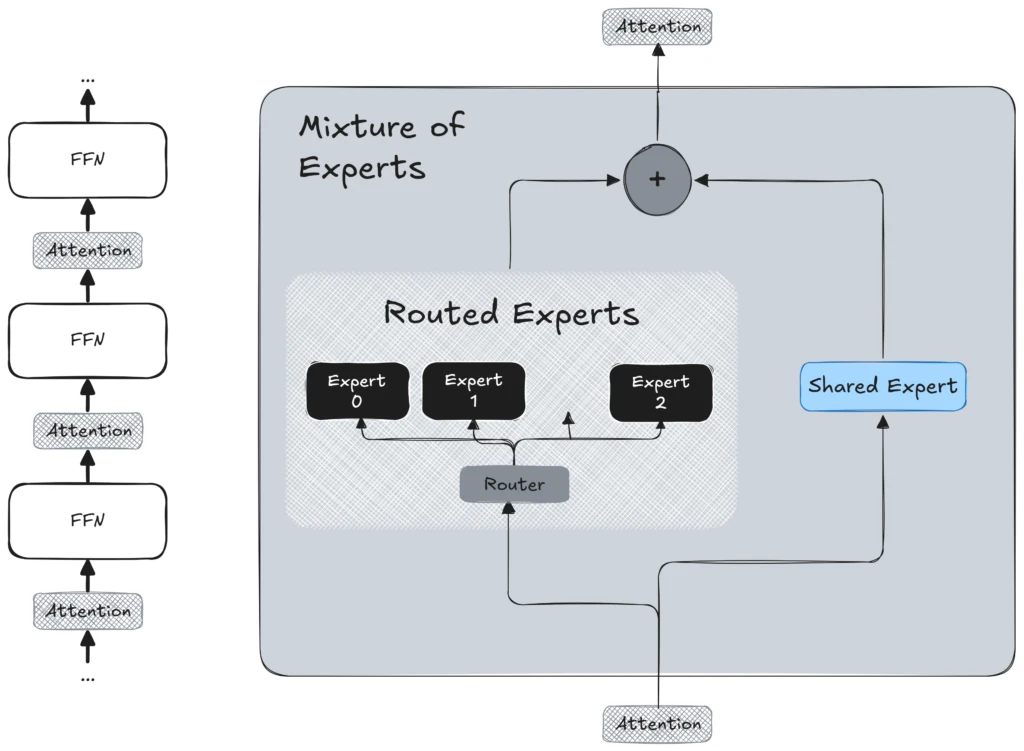
According to Meta, two key innovations set Llama 4 apart: native multimodal support with early fusion and a sparse Mixture of Experts (MoE) design for efficiency and scale.
- Early-fusion multimodal transformer: Llama 4 uses an early fusion approach, treating text, images, and video frames as a single sequence of tokens from the start. This enables the model to understand and generate various media together. It excels at tasks involving multiple modalities, such as analyzing documents with diagrams or answering questions about a video’s transcript and visuals. For enterprises, this allows AI assistants to process full reports (text + graphics + video snippets) and provide integrated summaries or answers.
- Cutting-edge Mixture of Experts (MoE) architecture: To achieve good performance without incurring prohibitive computing expenses, Llama 4 utilizes a sparse Mixture of Experts (MoE) architecture. Essentially, this means that the model comprises numerous expert sub-models, referred to as “experts,” with only a small subset active for any given input token. This design not only enhances training efficiency but also improves inference scalability. Consequently, the model can handle more queries simultaneously by distributing the computational load across various experts, enabling deployment in production environments without necessitating large single-instance GPUs. The MoE architecture allows Llama 4 to expand its capacity without escalating costs, offering a significant advantage for enterprise implementations.
Meta built Llama 4 with the best practices outlined in their Developer Use Guide: AI Protections. This includes integrating mitigations at each layer of model development from pre-training to post-training and tunable system-level mitigations that shield developers from adversarial attacks. And, by making these models available in Azure AI Foundry, they come with proven safety and security guardrails developers come to expect from Azure.
We empower developers to create helpful, safe, and adaptable experiences for their Llama-supported applications. Explore the Llama 4 models now in the Azure AI Foundry Model Catalog and in Azure Databricks and start building with the latest in multimodal, MoE-powered AI—backed by Meta’s research and Azure’s platform strength.
The availability of Meta Llama 4 on Azure AI Foundry and through Azure Databricks offers customers unparalleled flexibility in choosing the platform that best suits their needs. This seamless integration allows users to harness advanced AI capabilities, enhancing their applications with powerful, secure, and adaptable solutions. We are excited to see what you build next.
